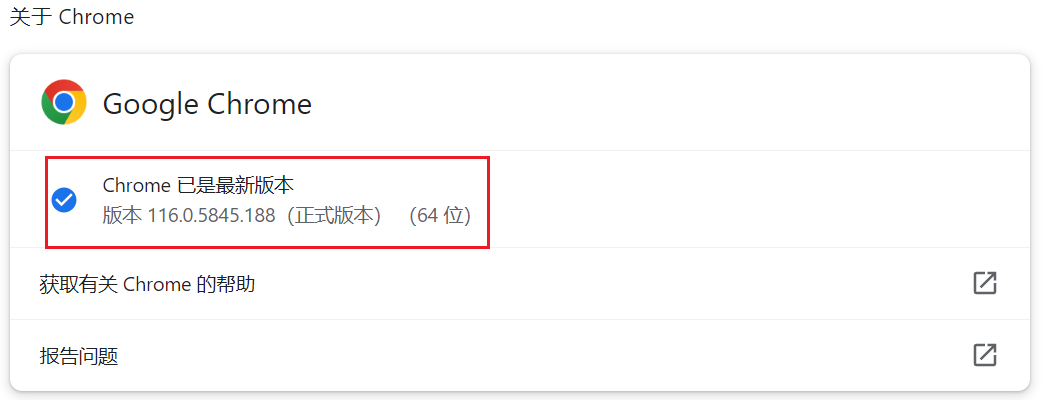
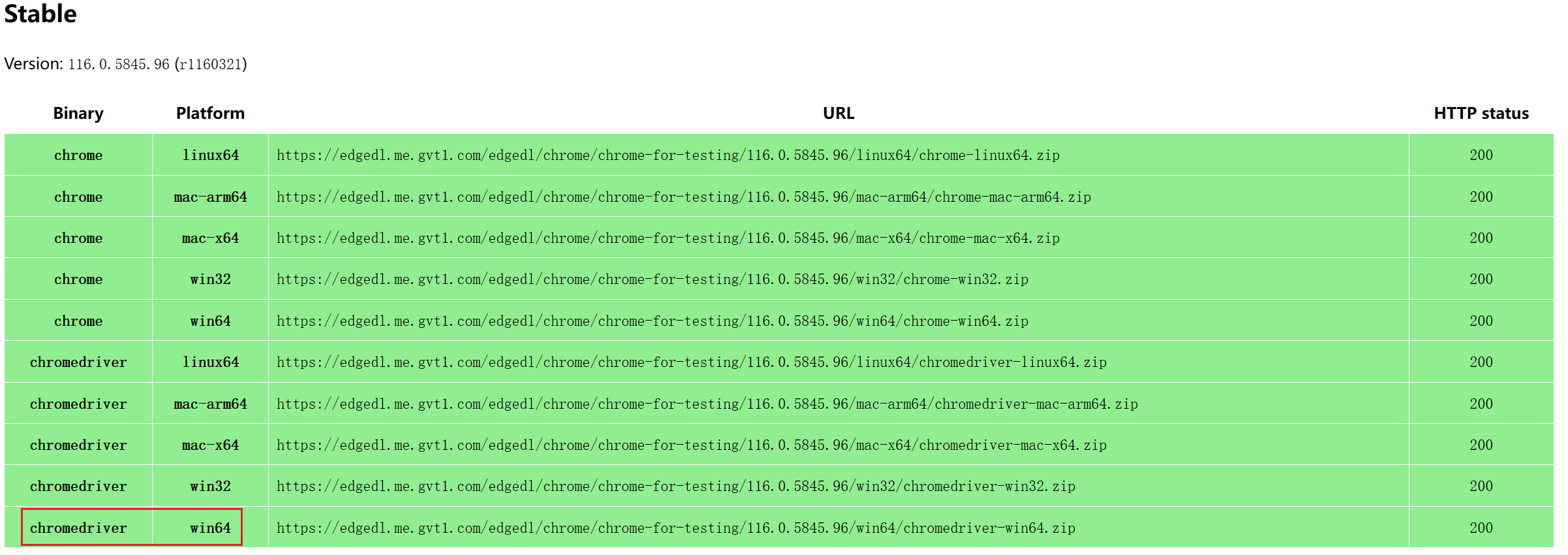
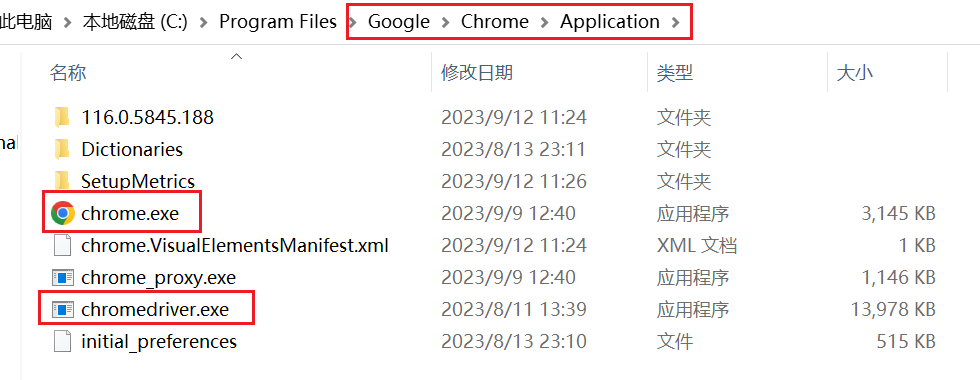
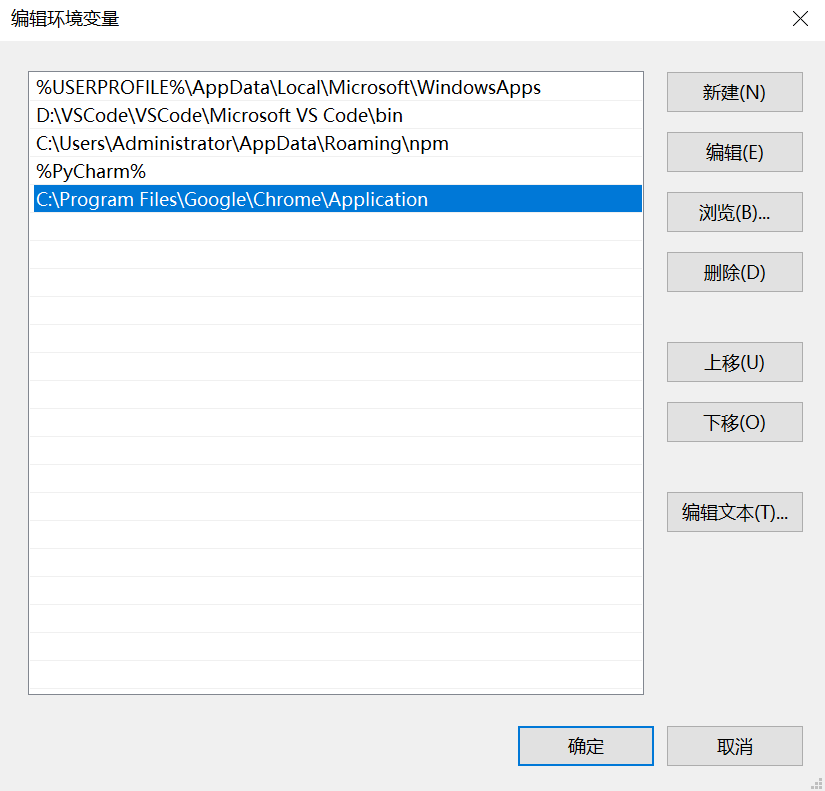
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ # 创建一个BeautifulSoup解析对象 soup = BeautifulSoup(html_doc, "html.parser", from_encoding="utf-8") # 获取所有的链接 links = soup.find_all('a') print("所有的链接") for link in links: print(link.name, link['href'], link.get_text())
所有的链接 a http://example.com/elsie Elsie a http://example.com/lacie Lacie a http://example.com/tillie Tillie 获取特定的URL地址 a http://example.com/elsie ['sister'] Elsie
selenium实现
Selenium是广泛使用的模拟浏览器运行的库,它是一个用于Web应用程序测试的工具。 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,并且支持大多数现代 Web 浏览器。因此可以利用Selenium进行爬虫操作。